Measuring the Quality of Your Data Pipeline
Introduction
HiveMQ Data Hub is an integrated policy engine in the broker that can validate, enforce, and manipulate data in motion. It helps organizations that have a large number of devices transmitting MQTT data to ensure data quality and integrity, ultimately maximizing the business value of the data that is transported by the HiveMQ platform.
Numerous data producers publish MQTT messages on an MQTT topic. On the consumer side, multiple services may process the data and build the desired application logic, which is generally called a data pipeline. In IoT use cases, the number of producers and/or data consumers can be incredibly large - even millions of consumers and producers are typical.
Managing an enormous number of clients is very challenging. However, devices that embed MQTT clients are continuously updated for bug fixing or adding new features. In certain circumstances, third-party vendors update their devices without further coordination with the data consumers, which may lead to unwanted and even costly downtimes of the application logic. Enforcing certain behaviors is necessary to keep producers and consumers decoupled.
MQTT Data Schemas and Policies
Data contracts in the form of data schema definitions, enhance the resiliency of data pipelines to keep data consumers up and running. In many development teams, those contracts are often made implicitly by writing a document or feature request. Consequently, without enforcing these contracts, failures are likely to occur. From the development team’s perspective, they are getting less autonomous since communication is often manually required for all of its data consumers.
For many years, techniques have been available to manage data contracts: Schema definition formats such as JSON schema or Protobuf are available to specify those contracts formally. When data producers update their data schemas, automated testing can detect flaws in data consumers that are no longer able to process the data, which leads to fixing those issues in development.
MQTT is data agnostic, i.e., the protocol doesn’t understand the data, and therefore MQTT clients do not typically validate their data. Additional frameworks and toolings are required to check the consumed or published data. Moreover, in most cases, low-powered devices don’t have the necessary computational resources to validate a schema.
Data consumers reading MQTT messages may be unable to process the message, which may eventually fail. A centralized MQTT broker can efficiently validate the data before reaching data consumers.
The HiveMQ Data Hub introduces the concept of schemas and policies. A schema can be any well-known data schema such as JSON schema or Protobuf. A policy, which is a textural and declarative description - defines how a data pipeline is handled in the broker, in particular, the schema validation.
An MQTT message can be considered valid or invalid based on whether it conforms to any of the provided schemas. If an MQTT message conforms to any of the schemas, it is considered valid; otherwise, it is deemed invalid. Depending on this determination, various actions can be taken, such as passing the message to its data consumers, dropping it, or rerouting it to another MQTT topic or any other data flow function. These scenarios are instrumental in maintaining decoupled data pipelines between producers and consumers.
We define a policy in three basic concepts:
Matching: A policy should match for specific criteria, e.g., a topic filter.
Validations: A set of validations is executed for each of those matching incoming MQTT message, e.g., a schema validation is executed.
Actions: The validation steps have two outcomes for which further actions need to be taken, e.g., logging a message, incrementing a metric, or even re-rerouting the MQTT message.
In the following, we introduce a quality metric for data pipelines composed of schema validation.
Measuring the Data Quality
A very simple data quality metric can be defined as follows:
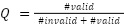
where #valid and #invalid is the number of valid and invalid MQTT messages, respectively.
A quality metric Q of 1 means that all incoming MQTT messages are valid, and a metric of 0 is the opposite. However, in most cases, the value is between 0 and 1. The target is to keep as close as possible to 1. Tracking that number helps operation and development teams increase the observability of the massive amount of clients so they can immediately take action when required.
Use Case
In this section, we demonstrate how to write a schema and a policy to derive a quality metric of your data pipeline. The demonstrator is available in our GitHub repository. Clone it out and try it yourself.
Consider the following use case: A customer has two manufacturing sites called Factory Berlin and Factory New York as visualized above. Both factories have many data producers publishing data into the topic factories/<factoryName> where factoryName is either factoryBerlin or factoryNewYork.
Schema
For the sake of simplicity, consider that all data producers publish MQTT messages according to the same schema. In this example, we simply consider JSON as a payload format.
{
"type": "object",
"properties": {
"id": {
"type": "string"
},
"type": {
"type": "string"
},
"version": {
"type": "string"
},
"timestamp": {
"type": "number"
},
"value": {
"type": "object"
}
},
"required": [
"id",
"type",
"timestamp",
"value"
]
}Consider the following example MQTT message according to the introduced schema:
Two machines are publishing their state into the MQTT topics:
factory/factoryBerlin/cutting-machineand
{
"id":,
"type" : "cutting-machine",
"version" : 1,
"value": {
"pressure": "78psi",
"packml_state" : "EXECUTE"
}
}factory/factoryNewYork/cleaning-machine
{
"id":,
"type" : "cleaning-machine",
"version" : 1,
"timestamp" : 1686046812,
"value": {
"consumption": "150lm",
"packml_state" : "EXECUTE"
}
}Let’s use the MQTT CLI tool to create the schema in the HiveMQ Data Hub (Release Notes).
mqtt hivemq schema create --id machine-schema --type JSON --file data-producers-schema.jsonThe schema is now created but has no effect yet. All data producers agreed to publish their data according to the schema we defined above. Data consumers that build the application logic expect precisely that kind of schema. Once any message deviates from the schema, it should be dropped such that data consumers read only valid messages to work reliably. This behavior is described in a policy defined in the next Section.
Policy
HiveMQ Data Hub introduces the concept of a policy. A policy specifies the behavior of the data flow of incoming MQTT messages. Consider the following policy:
{
"id":"global-factory-policy",
"matching":{
"topicFilter":"factory/#"
},
"validation":{
"validators":[
{
"type":"schema",
"arguments":{
"strategy":"ALL_OF",
"schemas":[
{
"schemaId":"machine-schema",
"version":"latest"
}
]
}
}
]
}
}The policy defines the following topic filter factory/#, that means all MQTT messages published to a topic prefixed with factory are checked by the policy.
Next, the policy defines the validation part. It specifies a schema validation. The schema with the id machine-schema we defined above should be validated. If the MQTT message is valid according to the schema, the overall validation part is successful.
There are no further actions defined in this policy which means the default behavior is executed, i.e.,
The MQTT message is valid according to the schema and is passed to the actual topic
The MQTT messages is invalid and is dropped, which means not published to the actual topic
The message shown in the previous section would be passed to the consumers since these are valid according to the schema. However, please consider the following MQTT message:
{
"id":,
"type" : "cutting-machine",
"version" : 1,
"value": {
"pressure": "78psi",
"packml_state" : "EXECUTE"
}
}The MQTT message is invalid since the timestamp field isn’t present but is required in the schema. Not adhering to the schema, the message will be dropped according to the default behavior.
This easy-to-use definition of schema and policy already solves the problem that consumers should only ready messages to the agreed schema.
Collect Data
As a next step, we want to compute the ratio between the valid and invalid messages leading to a quality metric. With the HiveMQ Platform version 4.16, custom metrics per policy can be created.
The following policy introduces two metrics good-machine-messages and bad-machine-messages, which define a metric counting valid and invalid MQTT messages, respectively.
Note: Each metric defined in a policy is prefixed by the string:
com.hivemq.data-governance-hub.data-validation.custom.counters
{
"id":"global-factory-policy-with-metric",
"matching":{...},
"validation":{...},
"onSuccess":{
"pipeline":[
{
"id":"goodFactoryMessagesMetric",
"functionId":"Metrics.Counter.increment",
"arguments":{
"metricName":"good-machine-messages",
"incrementBy":1
}
}
]
},
"onFailure":{
"pipeline":[
{
"id":"badFactoryMessagesMetric",
"functionId":"Metrics.Counter.increment",
"arguments":{
"metricName":"bad-machine-messages",
"incrementBy":1
}
}
]
}
}The behavior in terms of message flow isn’t affected at all. This means if the MQTT message is valid according to the schema the message is published, otherwise if invalid the message is dropped. That means, even though we see invalid messages counted in the metric, the data consumers read only valid messages and stay healthy.
Since we need to replace the old policy global-factory-policy with a new policy `global-factory-policy-with-metric, please remove the policy by executing the following command, first:
mqtt hivemq data-policy delete --id global-factory-policy
After deleting the global-factory-policy, please run the following command to create the new policy with the new metrics:
mqtt hivemq data-policy create --file global-factory-policy-with-metric.json
Show Me The Numbers
With the latest policy we created, two new metrics are introduced. Each message published to the topic filter factory/# is checked for a valid schema and then, based on the respective outcome, the metric is incremented. We want to use the metrics to compute the quality metric as defined above. In our example, we use Prometheus and the HiveMQ Prometheus Extension to gather metrics from HiveMQ Enterprise and to compute the actual metric. To visualize the metrics, we use Grafana. The complete setup is also contained in the GitHub repository. The following ratio is executed as PromQL to compute the quality metric Q.
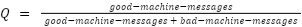
The following Grafana dashboard visualizes the quality metric on top very prominently.
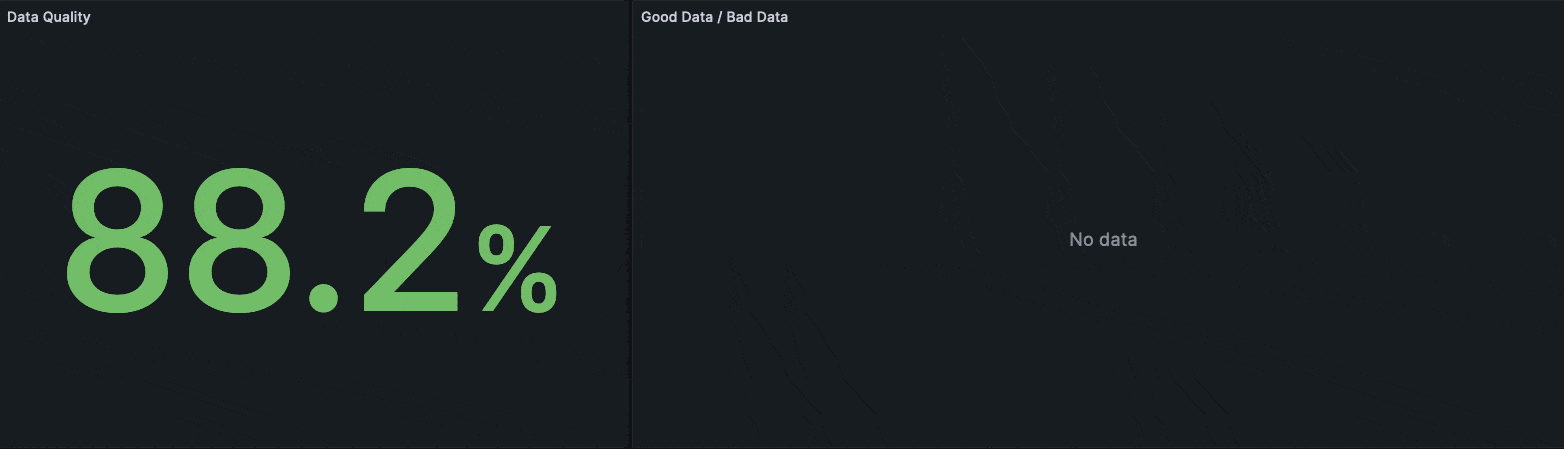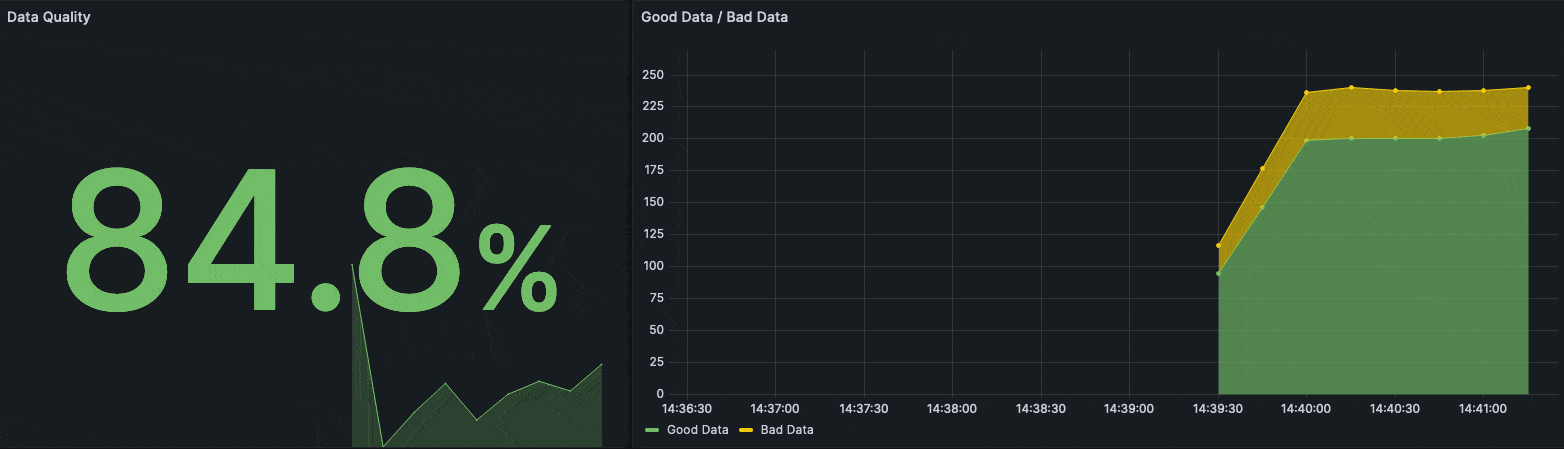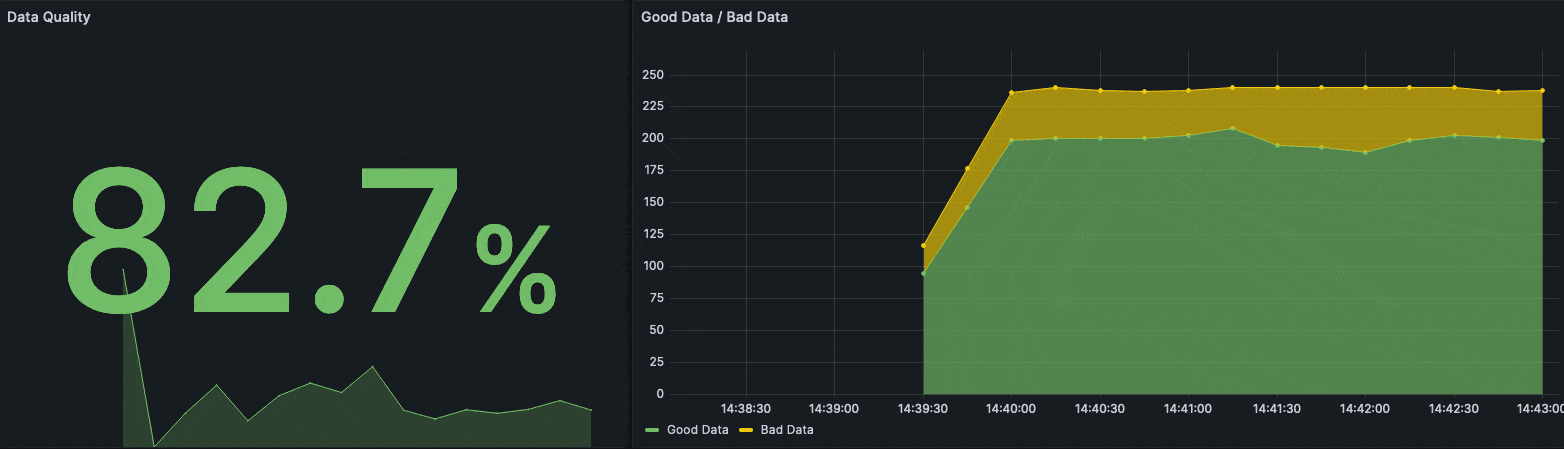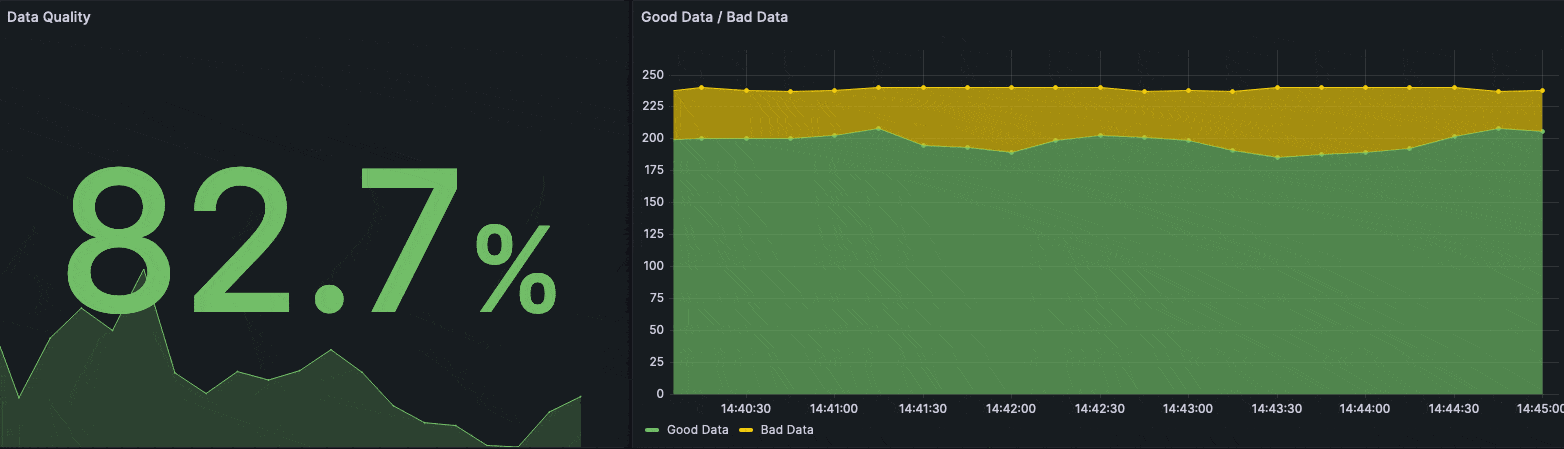
Grafana dashboard visualizing the quality metric
Conclusion
The introduction of MQTT data schemas and policies addresses the critical issue of enhancing the resilience of data pipelines. By formally specifying data contracts and automating schema validation, development teams can achieve greater autonomy and reliability in their data processing workflows.
The HiveMQ Data Hub presents a powerful solution for organizations dealing with the challenges of managing large-scale MQTT data pipelines. With the ability to validate, enforce, and manipulate data in motion, it ensures the quality and integrity of data transmitted through the HiveMQ MQTT Platform.

