Creating IIoT Data Pipeline Using MQTT and Kafka: A Step-By-Step Guide
Introduction
In this article, I will walk you through the steps on how to integrate MQTT data from a HiveMQ broker cluster on Azure into an Apache Kafka Cluster on Confluent Cloud. Essentially, creating a data pipeline for your Industrial IoT solution using MQTT and Apache Kafka.
Demo Setup
To demonstrate, I’m going to use this demo station that consists of devices that you’d typically find in an industrial facility.
 Source - Demo Station to demonstrate a data pipeline using MQTT and Apache Kafka
Source - Demo Station to demonstrate a data pipeline using MQTT and Apache Kafka
I’ll simulate an industrial boiler using sensors, and then I’ll create an MQTT and Kafka pipeline to move the boiler data from the edge of my studio to a data center in the cloud.
But before diving into the demo, let’s examine why we need to combine MQTT and Kafka to build such data architecture.
IIoT Data Architecture Using MQTT and Kafka
To understand why you need an MQTT and Kafka data pipeline, we need to frame just how much manufacturing data moves. To do that, let’s compare a typical Industrial IoT scenario with a simple commercial IoT solution.
Say you have a vehicle tracking IoT solution; you’d typically read and publish about five to ten data points (such as location, gas level, weight, etc.) every minute. In contrast, if we had a cookie or sweet factory, it is not uncommon to find a furnace with over 1000 measurements that you need to read and process every second. And your cookie factory may have many of these data-intensive furnaces.
When you do the math, you quickly notice that your Industrial IoT solution requires streaming and processing millions of data samples daily. And as your company grows, you need to stream more real-time data will also increase.
So, in the cookie factory example, we need a real-time data infrastructure Industrial IoT solution that persistently processes large volumes of data reliably at scale, making it readily available for enterprise applications. This setup becomes a value-add for the organization. Adding Kafka to the mix will allow us to provide massive amounts of reliable storage and distribution systems with high throughput. It is a buffer for the real-time information streams from your industrial facility. In perfect timing, Kafka feeds these data streams into multiple enterprise applications such as Data Science and Analytics apps.
However, Kafka is not well suited for structuring communication with Industrial IoT devices and sensors. Contrarily, this is a domain in which MQTT shines. Let us look at a couple of reasons why that is the case.
| MQTT | Apache Kafka |
|---|---|
| Built for constraint devices | Built for data centers |
| Dynamically scales to millions of topics | Can not handle large numbers of topics |
| Default protocol in many IoT devices | No native connection to IoT devices |
| Broker accessed through load balancer | Broker needs to be addressed directly |
| No Keep-Alive or Last Will & Testament |
 Firstly, Kafka is built for data center environments with stable networks and ‘unlimited’ computing resources. However, IIoT components (devices, sensors, etc.) usually don’t have the luxury of being housed in these resource-rich centers. Instead, they run in harsh environments where network connections are unreliable. Due to its lightweight nature, MQTT is exceptional in resource-constrained settings.
Firstly, Kafka is built for data center environments with stable networks and ‘unlimited’ computing resources. However, IIoT components (devices, sensors, etc.) usually don’t have the luxury of being housed in these resource-rich centers. Instead, they run in harsh environments where network connections are unreliable. Due to its lightweight nature, MQTT is exceptional in resource-constrained settings.
Secondly, Kafka cannot handle large amounts of topics and connected devices. On the other hand, MQTT is built for dynamically scaling hundreds of millions of topics on a single cluster.
Furthermore, most Industrial IoT devices and sensors can’t connect to Kafka natively due to a Kafka client’s resource-intensive and complex requirements.
To compound this difficulty, each broker in a Kafka Cluster needs to be addressed directly. Meanwhile, MQTT broker cluster connects devices to a broker through a load balancer.
One last thing worth mentioning is the fact that Kafka does not deploy crucial delivery features for IoT, such as keep Alive and Last Will and Testament which MQTT implements.
It’s plain to see why the strongest Industrial IoT data pipeline uses MQTT to structure communication with devices and sensors, and Kafka to integrate the data from devices to business applications in a data center.
Demo - Steps to Follow
In this demo, I will move through the following steps:
Deploy a HiveMQ MQTT broker cluster on Azure Cloud.
Use Node-Red to collect data from industrial devices in my demo setup, convert it into JSON format, and
Publish the data as MQTT messages to the HiveMQ broker cluster.

Create a Kafka cluster on Confluent Cloud, and then
Use the HiveMQ Kafka extension,which implements the native Kafka protocol inside the HiveMQ MQTT broker, to forward the MQTT messages to the Kafka cluster on Confluent Cloud. There it will be made available for consumption by a large number of enterprise applications.
Let’s get started.
Deploying HiveMQ MQTT Broker on Azure Cloud
In this first step, I’ll show you how to deploy a HiveMQ MQTT broker cluster on Azure Cloud. First, visit the HiveMQ Github Repo for Azure cluster discovery extensions.
In the Repo, select the Arm Quickstart Templates directory. From the directory, click on the Deploy to Azure button.
 Source - HiveMQ Broker Cluster deployment page
Source - HiveMQ Broker Cluster deployment page
This will take me to my Azure Portal, and present an interface that allows me to customise my deployment.
I’ll leave my subscription account as default.
Next, I’ll create a new resource group, and call it hivemq_demo.
Leave the selected region as East US.
Next, I enter admin username for this deployment, which I’ll call hivemq_admin.
 This is the screen for configuring broker cluster instance details
This is the screen for configuring broker cluster instance details
Under Authentication Type, keep it at password.
Then I’ll enter my password.
Next, I’ll enter the HiveMQ MQTT broker version that I want to deploy.
By default, this deployment deploys two nodes for your MQTT broker cluster, and you can select to deploy more or less modes.
For demonstration purposes, I’ll deploy one node for my cluster.
 This is the screen for configuring broker version and number of instances
This is the screen for configuring broker version and number of instances
Next I’ll click on Review and Create. Then click on Create to start the deployment.
 This is the screen that shows a successful validation check
This is the screen that shows a successful validation check
When my deployment is complete, I’ll click on go-to resources.
Here you’ll notice that my deployment has provisioned several Azure services, including a virtual machine, storage account, and load balancer.
 This is the screen that shows Azure services provisioned during deployment
This is the screen that shows Azure services provisioned during deployment
To get the public IP address of my cluster, I’ll select the HiveMQ load balancer public IP.
 This is the screen that shows public IP of a HiveMQ broker cluster
This is the screen that shows public IP of a HiveMQ broker cluster
To confirm that my deployment was successful, I need to access the HiveMQ Control Center of my HiveMQ Broker Cluster. So, I’ll copy the IP address and use it to access the control center at port 8080.
Then I’ll use the HiveMQ default username and password.
 This is the screen that shows HiveMQ Control Center dashboard
This is the screen that shows HiveMQ Control Center dashboard
Now that I’ve successfully accessed the control center it confirms that my HiveMQ MQTT Broker Cluster deployment was successful and it is now ready to receive messages.
To forward MQTT messages from my broker to a Kafka Cluster, I’ll need to activate and configure the HiveMQ Kafka extension accordingly.
But before I can do that, I must deploy the Kafka cluster and get the details to put in my Kafka extension configuration file.
Publishing Plant-Floor Data Through MQTT + Kafka Pipeline
Now I’m going to show you how to publish MQTT data from my demo station to my HiveMQ Broker Cluster on Azure.
I’ve got a Groov Rio Remote IO device connected to some sensor inputs that simulate a Plant Boiler.
Below is a visual of this setup. I’m collecting the sensor data from my GroovRio device via OPC UA and feeding it into my Ignition SCADA software.
 This is the screen that shows Ignition SCADA visualization of demo plant
This is the screen that shows Ignition SCADA visualization of demo plant
What you see above is the interface of my Ignition SCADA software showing live data representing a Plant Boiler. Data Points include Boiler Temperature, Tank Level, Feed Water Flow Rate, and Output Steam Flow Rate.
To publish this information to my HiveMQ MQTT Broker Cluster, I use Node-Red which runs on my remote io device.
So I’ll open my Node-Red interface.
 This is the screen that shows Node-Red flow for publishing MQTT messages
This is the screen that shows Node-Red flow for publishing MQTT messages
The screenshot above is the Node-Red Flow that is reading the Boiler sensor data, packaging it into a JSON object, and then publishing it to my HiveMQ MQTT broker on Azure. For demonstration, I’m publishing every 5 seconds.
When I open the Publish to HiveMQ broker node ion the Node-Red flow above, you’ll see my HiveMQ Broker Cluster connection details.
 This is the screen that shows the MQTT client configuration on Node-Red
This is the screen that shows the MQTT client configuration on Node-Red
I’m publishing this data to a topic called plant/boilers.
 This is the screen for configuring MQTT topic on Node-Red
This is the screen for configuring MQTT topic on Node-Red
For more context, I’ve simulated data for a second Boiler, and placed it on a second Node-Red Flow.
I’m publishing the Boiler02 data to the same HiveMQ MQTT Broker on Azure, under the same topic, plant/boilers.
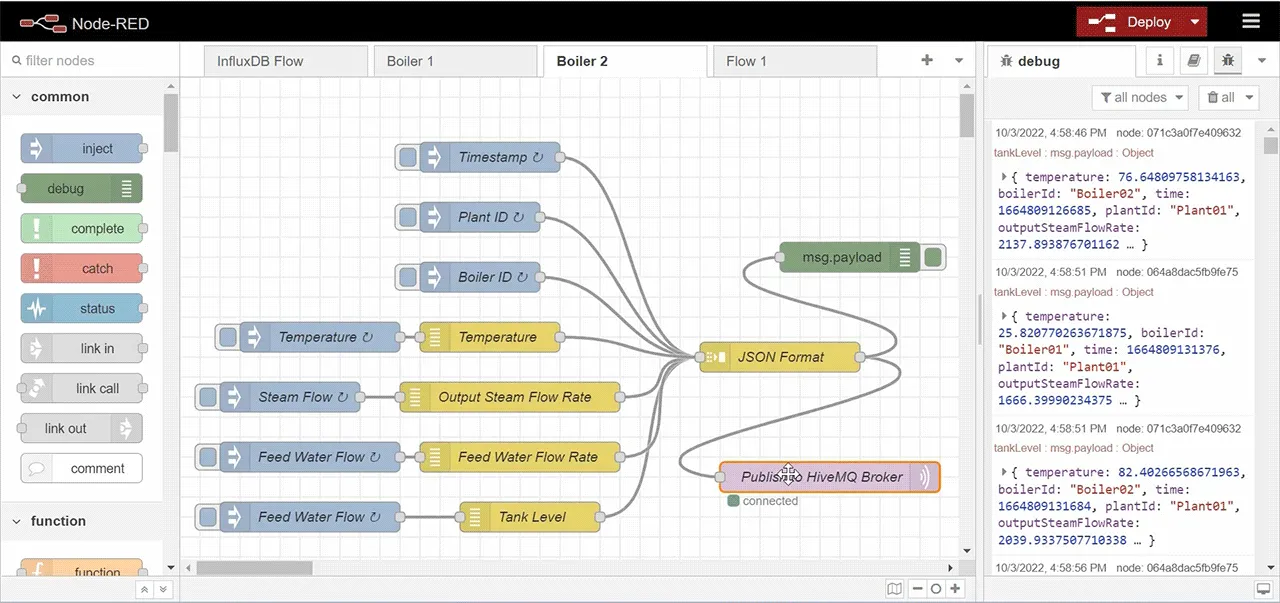 This is the screen that shows Boiler 2 Node-Red flow for publishing MQTT messages
This is the screen that shows Boiler 2 Node-Red flow for publishing MQTT messages
Before we move on, let’s take a look at the structure of the two JSON objects that I’m publishing to my HiveMQ MQTT broker.
Boiler 1 JSON Object
{
"time":1664808476206,
"plantId":"Plant01",
"boilerId":"Boiler01",
"temperature":25.738861083984375,
"outputSteamFlowRate":1665.9998779296875,
"feedWaterFlowRate":36.65599822998047,
"tankLevel":60.50371131548436
}
Boiler 2 JSON Object
{
"time":1664808301485,
"plantId":"Plant01",
"boilerId":"Boiler02",
"temperature":73.19016881555297,
"outputSteamFlowRate":2168.589516638531,
"feedWaterFlowRate":42.313906323292606,
"tankLevel":60.918631402915594
}Now, to find out if MQTT messages published from Node-Red are actually reaching my HiveMQ Broker Cluster, I’ll use an MQTT client software called MQTT.fx.
I’m already connected to my broker, so I’ll go ahead and subscribe to plant/boilers.
When I do that you can see that I’m receiving Boiler01 and Boiler02 data from my Demo Station.
 This is the screen that shows MQTT message reception on MQTT.fx
This is the screen that shows MQTT message reception on MQTT.fx
I’ve deployed my HiveMQ MQTT Broker on Azure, and am again successfully publishing Boiler data to the broker.
What I want to do now is forward this data to an Apache Kafka Cluster using my HiveMQ Kafka Extension.
But to do that, I need to create the Apache Kafka Cluster on Confluent Cloud. So, I’ll do that next.
Deploying Confluent Cloud Kafka Cluster on Azure
Now I’m going to show you how to create an Apache Kafka Cluster on the Confluent Cloud Platform.
On the Confluent Cloud Page, I’ll click Get Started Free.
 This is the screen that shows Confluent Cloud home page
This is the screen that shows Confluent Cloud home page
I’ll sign in using my Google Account.
When I’m logged in, and I’ll create a Basic Kafka Cluster.
 This is the screen that shows cluster creation options on Confluent Cloud
This is the screen that shows cluster creation options on Confluent Cloud
Next, select Azure cloud for hosting. Then I’ll leave EastUS selected under Region, and Single Zone selected under Availability (as shown below in the screenshot).
 This is the screen that shows cloud platform and region for cluster deployment
This is the screen that shows cloud platform and region for cluster deployment
Click on Continue.
Then name my cluster. I’ll call it demo_cluster.
 This is the screen that shows the assignment of cluster name
This is the screen that shows the assignment of cluster name
Click on the Launch Cluster button
With this final step in this sequence, I’ve successfully created an Apache Kafka Cluster on Confluent Cloud.
 This is the screen that shows Cluster Overiew on Confluent Cloud
This is the screen that shows Cluster Overiew on Confluent Cloud
Now that my Kafka Cluster is running, I need to create a Kafka Topic to which I’ll be streaming Boiler IoT data from my HiveMQ MQTT Broker.
To do this, I’ll click on Topics.
 This is the screen that shows topic creation on Confluent Cloud
This is the screen that shows topic creation on Confluent Cloud
Then create a new topic.
I’ll call my topic boilers and assign three (3) partitions to it.
 This is the screen that shows topic name and assignment of partitions
This is the screen that shows topic name and assignment of partitions
Then I’ll proceed by clicking on Create with defaults.
This successfully deploys my Kafka cluster and creates a topic.
To allow my HiveMQ MQTT Broker to connect to this Kafka Cluster, I need to get the connection details found on the Cluster settings page.
 This is the screen that shows the cluster Bootstrap server URL
This is the screen that shows the cluster Bootstrap server URL
First, I’ll need to copy the Bootstrap server URL highlighted in the above screenshot.
In addition to the Bootstrap server URL, I need to generate an API key and Secret pair to use as an authentication mechanism for my HiveMQ Kafka Extension.
To set this up I’ll go under API keys and click on Add Key to generate the Key and Secret.
 This is the screen that shows API key generation page
This is the screen that shows API key generation page
I’ve pre-done this stept, which means I have all the details I need to start transmitting MQTT data to my Kafka Cluster on Confluent Cloud.
With these Kafka Cluster settings and authentication details, I can configure my HiveMQ Kafka Extension to forward MQTT data to this cluster.
Forwarding MQTT Messages From HiveMQ to Confluent Cloud
Now I will show you how to configure the HiveMQ Kafka Extension to enable the broker to forward MQTT messages to the Kafka Cluster.
First, I need to access the Kafka Extension configuration file.
To do that, I will use Putty to SSH into the Azure Virtual Machine where my HiveMQ Broker was deployed.
 This is the screen that shows Putty connection to Azure Virtual machine
This is the screen that shows Putty connection to Azure Virtual machine
I’ll enter the Pubilc IP address of my broker cluster.
Click OK.
Next, login to the Virtual Machine. I use the details I set during the deployment of my broker cluster.
To ensure I have root access I type in the following command.
sudo -iNow I need to go to the directory of my VM that stores the application program files.
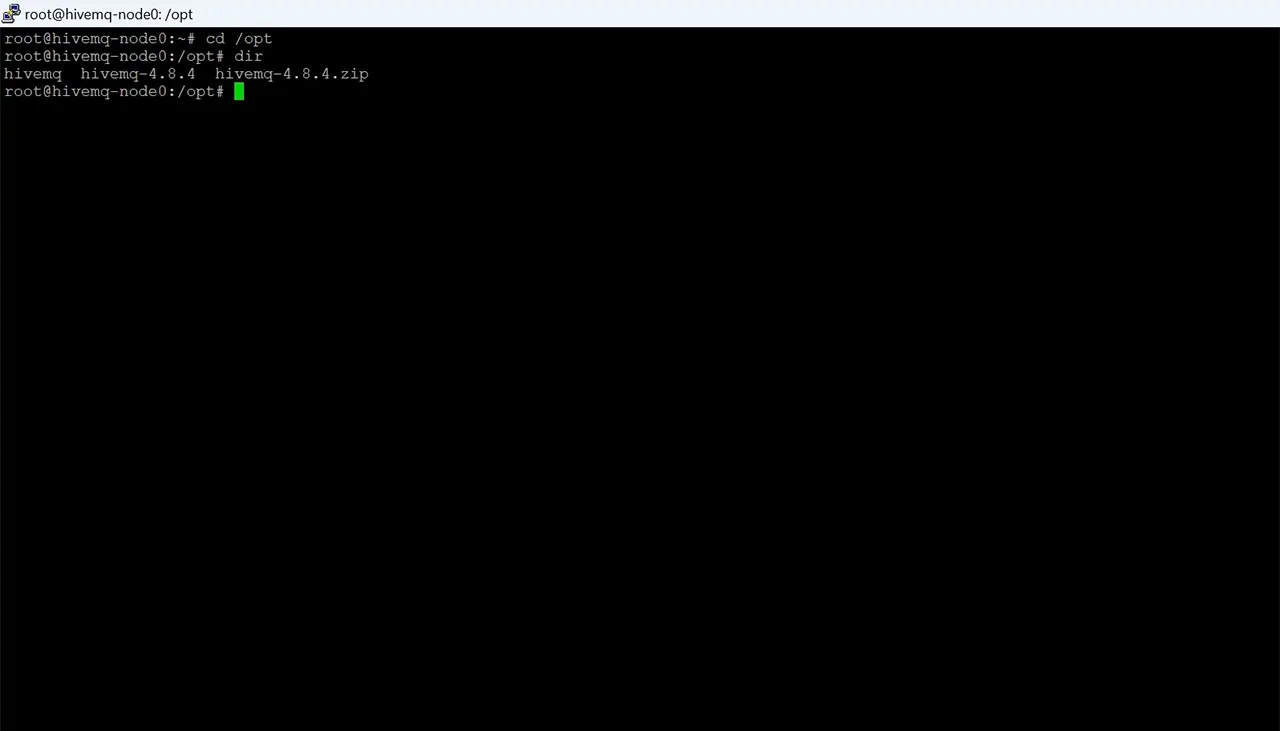 This is the screen that shows navigation to program file directory
This is the screen that shows navigation to program file directory
Then I’ll go into the HiveMQ directory.
 This is the screen that shows navigation to HiveMQ broker directory
This is the screen that shows navigation to HiveMQ broker directory
Next, I’ll go into the extensions directory.
 This is the screen that shows navigation to the Extensions directory
This is the screen that shows navigation to the Extensions directory
Then open the hivemq-kafka-extension directory.
 This is the screen that shows navigation to Kafka extension directory
This is the screen that shows navigation to Kafka extension directory
Once I’m inside the kafka extension directory, I’ll remove the DIASBLED to enable my Kafka extension.
Then I’ll rename the kafka-configuration.example.xml to kafka-configuration.xml
 This is the screen that shows how to enable Kafka Extension
This is the screen that shows how to enable Kafka Extension
When that is done, I’ll open up the kafka-configuration.xml file.
 This is the screen that shows the kafka Extension configuration details
This is the screen that shows the kafka Extension configuration details
This is what my HiveMQ Kafka Extension config file looks like after I’ve entered the Confluent Cloud Kafka Cluster details.
I have included the Bootstrap Servers URL address.
Then I enabled TLS.
Then under the authentication tag, I used my Confluent Cloud API key as the username and my API Secret as the password.
Next, under MQTT to Kafka Mapping, I entered the plant/boilers topic under mqtt-topic-filter. This is the MQTT topic in which my demo unit is publishing the boiler data. Essentially this specifies that I’d like all MQTT data on this topic to be forwarded to my Kafka Cluster.
Then finally, under kafka-topic, I specify my Kafka Topic to which I need all this data forwarded, which is boilers.
It’s important to note here that I don’t need to restart my HiveMQ broker after saving this config file. It does a hot reload.
I’ll go back to the dashboard to confirm that the connection to my Kafka Cluster on Confluent Cloud was successfully established.
 This is the screen that shows Kafka Extension dashboard on HiveMQ Control Center
This is the screen that shows Kafka Extension dashboard on HiveMQ Control Center
You can see that Kafka now appears on the sidebar, and the current status says All checks successful.
Now let’s go back to my Confluent Cloud Platform to see if we are getting any data.
I’ll navigate to Topics.
Then go to Messages.
 This is the screen that shows MQTT data reception on Confluent Cloud
This is the screen that shows MQTT data reception on Confluent Cloud
Here you can see that I am indeed forwarding MQTT data from the HiveMQ MQTT Broker to my Kafka Cluster on Confluent Cloud.
Conclusion
I’ve successfully created an IIoT data pipeline for collecting data from a plant-floor. I published it to a HiveMQ MQTT Broker, forward it to a Confluent Cloud Apache Kafka Cluster, which provided an output that could be consumed by a multiple number of enterprise applications.
This example demonstrates only two data points, however, large systems may involve millions of data points which would require many MQTT broker cluster nodes and multiple Kafka broker clusters and topics.
Hopefully you’ve also walked through these steps and find the possibilities endless.
Check out the video below that provides the summary of this blog
Chapters

Kudzai Manditereza
Kudzai is a tech influencer and electronic engineer based in Germany. As a Sr. Industry Solutions Advocate at HiveMQ, he helps developers and architects adopt MQTT, Unified Namespace (UNS), IIoT solutions, and HiveMQ for their IIoT projects. Kudzai runs a popular YouTube channel focused on IIoT and Smart Manufacturing technologies and he has been recognized as one of the Top 100 global influencers talking about Industry 4.0 online.



