Shared Subscriptions
Shared subscriptions allow the MQTT broker to balance the load of a single subscription across multiple MQTT clients. Until the release of MQTT 5, shared subscriptions were a unique feature of HiveMQ. Now, shared subscriptions are a standard feature of MQTT 5.
In a regular MQTT subscription, each client that subscribes to a topic receives a copy of every message that is published on the topic.
In an MQTT shared subscription, each client that shares the same subscription receives messages that are published with the shared topic in an alternating fashion.
Shared subscription is sometimes called client load balancing since the message load of a single topic is distributed across all the clients that subscribe to that topic.
Shared Subscription Topic Structure
Clients can subscribe to a shared subscription with standard MQTT mechanisms. Shared subscriptions have the following topic structure:
$share/SHARE_NAME/TOPIC
Each shared subscription has three parts:
-
A static shared subscription identifier (“$share”)
-
The name of the shared subscription (share name)
-
The specific topic subscriptions (can include wildcards)
Here is an example subscriber:
$share/my-shared-subscribers/myhome/groundfloor/+/temperature.
When multiple MQTT clients that have the same share name subscribe to the same topic, HiveMQ distributes the message among each of the MQTT clients in an alternating fashion.
| Subscriptions that have the same share name but different topics are handled as separate shared subscriptions. |
Use Cases
The load balancing capabilities that shared subscriptions provide are particularly useful in scenarios that require a high level of scalability. Here are a few common uses cases where shared subscriptions excel:
-
MQTT clients in the system cannot handle the load on subscribed topics individually.
-
Worker (backend) applications ingest MQTT streams and must be able to scale horizontally.
-
Intra-cluster node traffic needs to be relieved by optimizing subscriber node-locality for incoming publishes.
-
Popular topics that have a higher message rate than other topics on the system create a scalability bottleneck.
Shared Subscription Concepts
In a standard publish/subscribe model, every subscriber gets a copy of every message that matches the subscribed topic. With shared subscriptions, each shared subscription acts as a proxy for multiple real subscribers. HiveMQ selects one subscriber of the shared subscription and delivers the message:
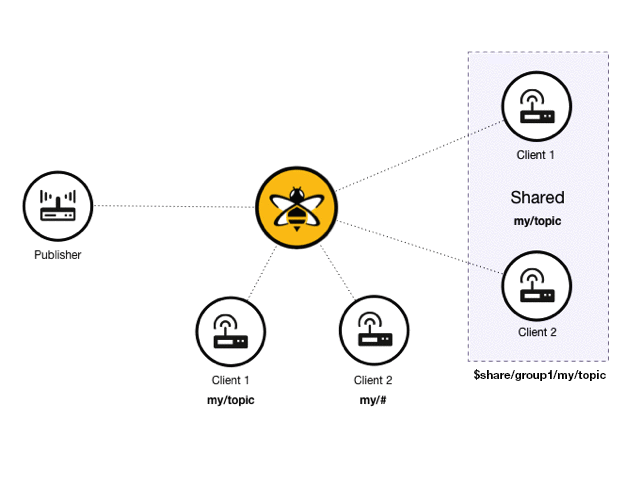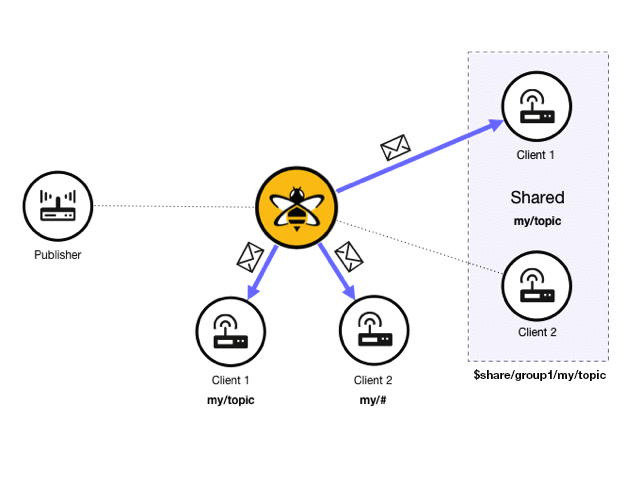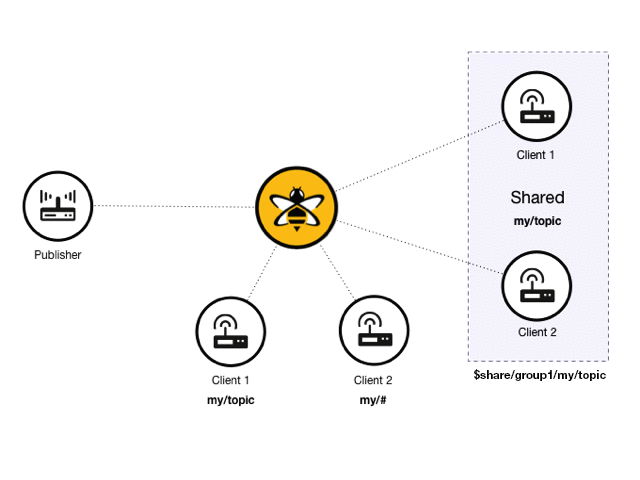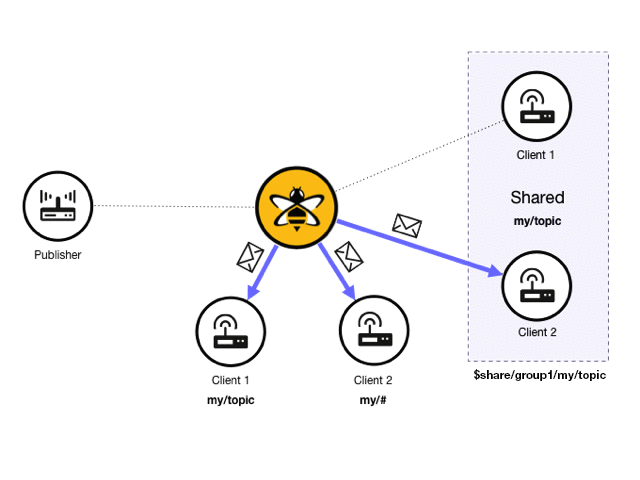
In a HiveMQ deployment, there can be an arbitrary number of shared subscriptions. For example, the following scenario is possible:
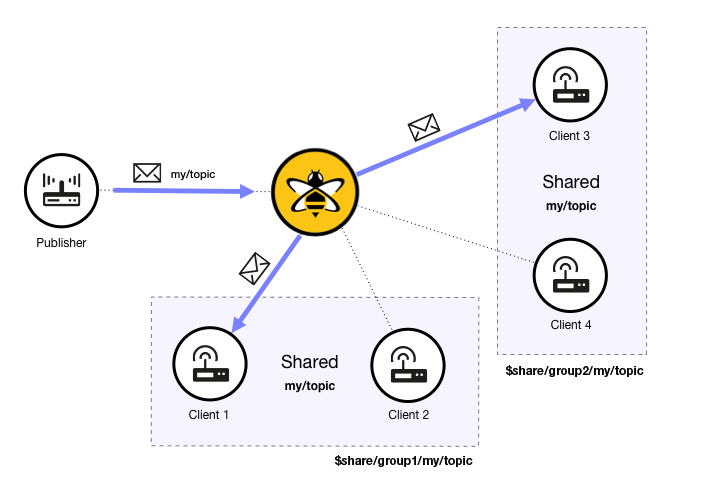
In this example, two different shared subscriptions have two subscribing clients. The groups have the same topic and different shared names. When a publisher sends a message with a matching topic, only one client of each shared subscription receives the message.
Shared Subscriptions in Cluster Deployments
Shared subscriptions are designed to dramatically alleviate cluster traffic and latency for high scalability deployments. For backend systems that need to ingest data via MQTT, shared subscriptions are the recommended way to connect horizontally scaling backend systems with HiveMQ.
Message Distribution
Messages are distributed across the shared subscribers in a way that minimizes cluster traffic. This method works best when the subscribers of the shared subscriptions are connected to different nodes in the cluster. Typically, subscribers that consume messages faster receive more messages.
| Messages are distributed randomly. A round-robin algorithm is not used for the message distribution (even on the same node). |
QoS Levels in Shared Subscriptions
Currently, it is not possible to guarantee QoS 2 in shared subscriptions because assumptions about the client state are needed.
| Shared subscriptions with QoS 2 are automatically downgraded to QoS 1. |
To avoid complex situations that are difficult to debug, we highly recommended that all shared subscribers for a group subscribe with the same Quality of Service level.
When members of a shared subscription group subscribe with different QoS levels, the shared-subscription algorithm honors the QoS level of each individual subscribing client.
For example, Client-1 subscribes to a shared subscription with QoS 0. Client-2 subscribes to the same shared subscription with QoS 1. Publishes with QoS 1 that match the shared subscription are sent to Client-1 with QoS 0 and to Client-2 with QoS 1. The QoS of the individual subscriptions apply. There is no global shared subscription QoS.
The best practice is to use the same QoS level for a shared subscription.
Message Queuing in Shared Subscriptions
As long as at least one subscribed client session is present, messages are queued for the shared subscription. When subscribed clients with a matching shared subscription reconnect or new clients subscribe to the same shared subscription, the clients start to receive the queued messages. Messages are also queued when the subscribers cannot consume the messages fast enough.
The message queue limit for each shared subscription is 500,000 messages.